E-R図 (Entity-Relationship Diagram)
関連モデルを図にしたのが、E-R図です。
E-R図では概念データモデルで記載した通りのエンティティ名だけを記述してリレーションするケースと、属性名も含めて詳細に記載するケースがあります。
データベースの設計としては、最初に概念を検討して徐々に詳細化していくため、最初はエンティティ名だけを記載して後で属性名を追加していくような流れになります。
E-R図は、データの構造をエンティティ (Entity)とリレーションシップ (Relationship)という2つの要素で視覚的に表現していきます。本ページではエンティティ名と属性名を記載したものについて解説していきます。
まず、データの集まりであるエンティティ(実体)を定義し、それらの間の関連(リレーションシップ)を明らかにしていきます。一般的に「データ定義」→「データ標準化」→「正規化」というプロセスを経て、E-R図を作成していきます。
E-R図を作成する大まかな流れは以下の通りです。
- エンティティの抽出:システムに必要なデータのまとまり(例:顧客、商品、注文)を洗い出します。
- エンティティの定義:各エンティティが持つ属性(例:顧客ID、氏名)を定義します。
- E-R図の作成:エンティティとリレーションシップを専用の記法で図に表します。
エンティティの定義例
データベース設計の章で記載したのと同じですが、以下にエンティティの定義例を示します。
問題
- 問題番号
- 問題内容
- 問題説明用画像URL
- 問題区分
- 問題表示区分
- 回答グループ番号
- 回答正解番号
- 回答の説明
- 参考URL
回答
- 回答グループ番号
- 回答内容
- 回答通番
問題分類
- 問題分番号
- 問題分類名
問題区分
- 問題区分番号
- 問題区分名
- 問題分類番号
IPA問題
- 親問題番号
- IPA区分
- 問題区分
- 問題年
- 問題番号
問題履歴
- 問題履歴番号
- ユーザID
- 問題番号
- 回答グループ番号
- 回答番号
- 問題表示時間
- 問題回答時間
- 正解判定
問題表示分類
- 問題表示区分番号
- 表示区分名
ユーザ
- ユーザID
- ニックネーム
- パスワード
- 性別
- 年代
- 作成日
ユーザ履歴
- 通番
- 変更前ユーザID
- 変更前ニックネーム
- 変更前パスワード
- 変更前性別
- 変更前年代
- 更新時間
「ユーザ」「問題データ」「問題回答ログ」がエンティティタイプ名、その下の項目(ユーザIDや実施年度など)が属性名です。エンティティ間の結びつきである線をリレーションシップと呼びます。
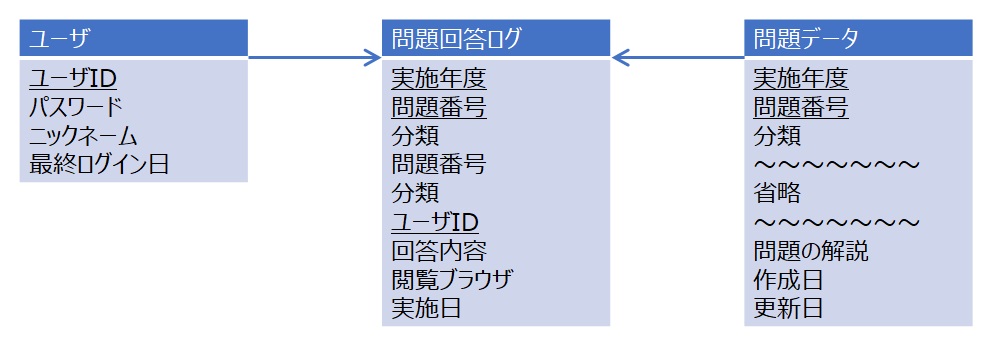
リレーションシップの多重度と存在条件
リレーションシップには「1対1」「1対多」「多対多」といった多重度(カーディナリティ)があります。これは、一方のエンティティのインスタンス(具体的なデータ)1件に対し、もう一方のエンティティのインスタンスが何件対応するかを示します。
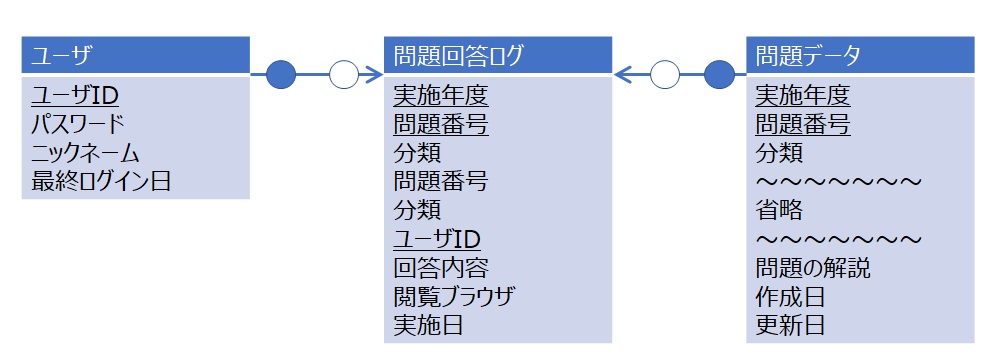
また、リレーションシップには存在が必須か否かを示す記法もあります。「●」は必須(1以上存在)、「○」は任意(0でもよい)を意味します。
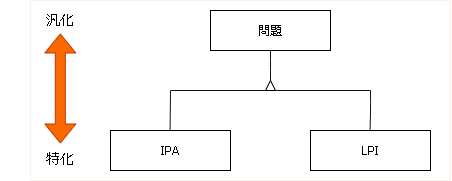
スーパータイプとサブタイプ
共通の属性を持つエンティティを汎化してスーパータイプとし、個別の属性を持つエンティティを特化してサブタイプとして階層構造で表現することができます。例えば、「問題」をスーパータイプとし、「IPA問題」と「LPI問題」をサブタイプとする関係です。これを「is-a」の関係(IPAは問題の一種である)と呼びます。
関係スキーマ
関係スキーマは、リレーショナルデータベースのテーブル構造をテキストで定義する表記法です。E-R図で設計した内容を、より具体的に表現します。
表記法: 関係名(属性名1, 属性名2, 属性名3, ...)
- 実線の下線: 主キー
- 破線の下線: 外部キー
また、属性間の関数従属(ある属性の値が決まると、別の属性の値が一意に決まる関係)も矢印(→)で表現します。
{実施年度, 問題番号} → 問題内容: 実施年度と問題番号が決まれば、問題内容が一意に決まる。ユーザID → ニックネーム: ユーザIDが決まれば、ニックネームが一意に決まる。
UML (Unified Modeling Language)
UMLは、E-R図と同様にデータやシステムの構造をモデル化するための標準的な記法の一つです。特にオブジェクト指向の考え方に基づいており、データベース設計ではクラス図がよく用いられます。
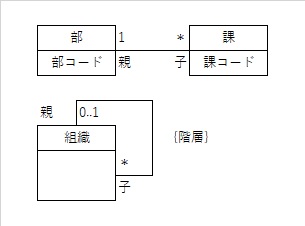
クラス図では、四角形(クラス)がエンティティに相当し、クラス名、属性、操作(メソッド)を記述します。クラス間の線は関連を表し、線の端にある数字で多重度を示します。
1- ちょうど1つ
*(または0..*)- 0個以上
1..*- 1個以上
5..10- 5個から10個まで
ビジネスモデルの理解
効果的なデータベースを設計するには、そのシステムがどのようなビジネスモデルに基づいているかを理解することが不可欠です。ビジネスモデルとは、利益を生み出すための仕組みや体系のことです。
データベースで扱うデータは、大きく2種類に分けられます。
- マスターデータ: 社員情報や商品マスタなど、業務の基礎となるデータ。頻繁には変更されません。
- トランザクションデータ: 商品の売上やシステムのアクセスログなど、日々の業務活動によって蓄積されていくデータ。ファクトデータとも呼ばれます。
ビジネスの要件を正確に把握し、これらのデータを適切にモデル化することが、優れたデータベース設計の鍵となります。