関係モデル(リレーショナルモデル)
関係モデル(リレーショナルモデル)とは、データを「リレーション」と呼ばれる二次元の表の集まりとして表現するデータモデルです。
データの集まりであるエンティティとエンティティ間の関連性を見える化して表現します。
このモデルでは、データは行(タプル)と列(属性)から構成されるテーブルで管理され、テーブル間の関連性を定義することで、複雑なデータを構造的に扱うことができます。
例えば、「ユーザ」テーブルと「問題履歴」テーブルが存在する場合、ユーザIDをキーとして両者を関連付けることで、「どのユーザがどの問題を解いたのか」という情報を効率的に管理できます。
関係モデルにおける主要な用語は以下の通りです。
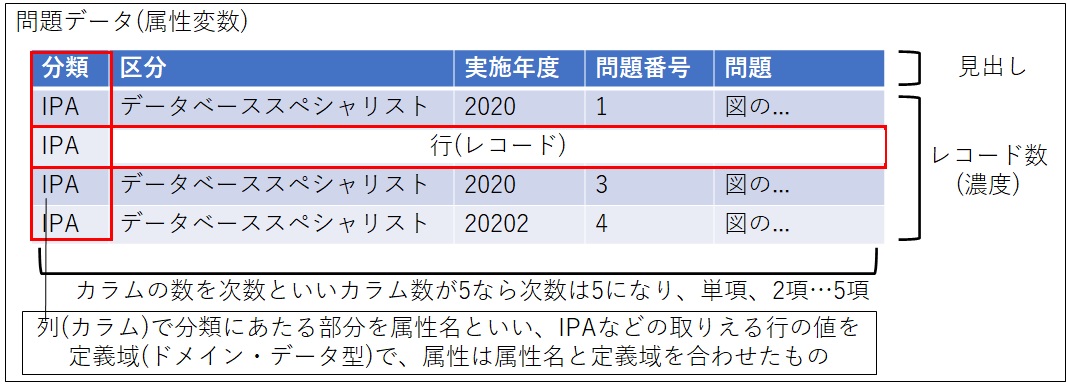
リレーショナルデータベースにおけるデータの基本的な格納単位で、一般的には「テーブル」や「表」と呼ばれています。Excelのシートのようなものをイメージすると分かりやすいです。
テーブルの中の「行」に相当するデータのまとまりで、「レコード」とも呼ばれます。例えば、顧客名簿テーブルであれば、顧客一人分の情報が1タプルにあたります。
テーブルの「列」にあたる部分で、「カラム」とも呼ばれます。その列にどのようなデータが格納されるかを示す「項目名」のことです。例えば、顧客名簿の「氏名」や「電話番号」などが属性です。
それぞれの属性(列)が持つことができる値の範囲や種類のことです。「年齢」という属性であれば、「0以上の整数」といったデータ型や制約がドメインとして定義されます。
次数はそのテーブルにいくつの属性(列)があるかを示す数で、濃度はそのテーブルにいくつのタプル(行)が格納されているかを示す数です。
キーの種類と役割
関係データベースでは、テーブル内の各行を一位に識別するために「キー」が非常に重要です。
主キー (Primary Key): テーブル内の各行を一意に識別するための列(または列の組み合わせ)です。主キーにはNULL値(空の値)を入れることはできず、重複も許されません。通常、連番(ID)などが用いられます。
複合キー (Composite Key): 複数の列を組み合わせて主キーとして使用するものです。例えば、「実施年度」と「問題番号」を組み合わせることで、特定の試験問題を一意に識別できます。
キーを理解するために、スーパーキーと候補キーという概念も知っておきましょう。
- スーパーキー: 行を一意に識別できる属性の「すべての」組み合わせです。例えば「ID, 氏名, メールアドレス」の組み合わせもスーパーキーです。
- 候補キー: スーパーキーの中から、行の識別に不要な属性を取り除いた「最小の」組み合わせです。候補キーは複数存在する場合があります。
そして、この候補キーの中から一つだけ選ばれたものが主キーとなります。選ばれなかった候補キーは代替キー(Alternate Key)と呼ばれます。
外部キー (Foreign Key): 他のテーブルの主キーを参照するための列です。これにより、テーブル間の関連性(リレーションシップ)を定義します。例えば、「注文履歴」テーブルに「ユーザーID」という外部キーを持たせることで、「ユーザー」テーブルと関連付けます。この外部キーの制約を参照整合性制約と呼びます。
関係代数
関係モデルでは、関係代数を使用してデータの操作を行います。詳細はSQLの章で解説しますが、ここでは基本的な概念を紹介します。
関係代数は、リレーション(テーブル)から必要なデータを取り出すための、手続き的な操作の体系です。SQLが「何が欲しいか」を宣言する非手続き的な言語であるのに対し、関係代数は「どのようにデータを取得するか」を定義します。SQLの内部的な動作を理解する上で重要な概念です。
射影 (Projection)
テーブルから特定の「列(カラム)」を抽出する操作です。SQLの`SELECT`句で列を指定する操作に相当します。
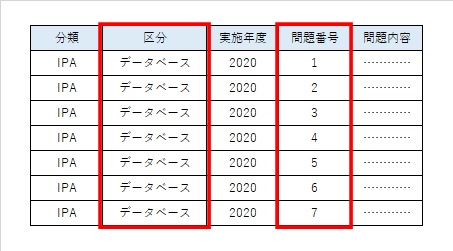
選択 (Selection)
テーブルから特定の条件に一致する「行(タプル)」を抽出する操作です。SQLの`WHERE`句に相当します。
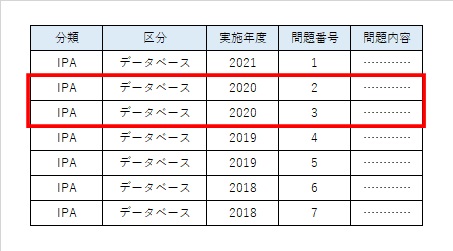
関係代数では $\sigma_{条件}(テーブル名)$ のように表記します。例えば、$\sigma_{実施年度=2018}(問題)$ となります。
結合 (Join)
複数のテーブルを、共通の列の値を使って一つのテーブルに結合する操作です。SQLの`JOIN`句に相当します。
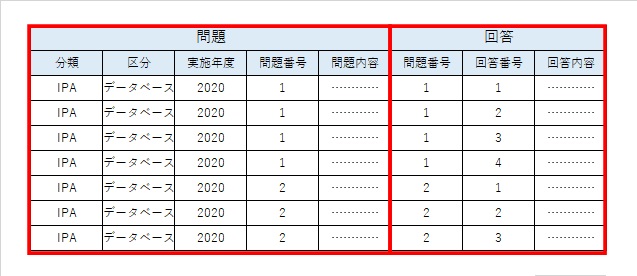
結合には、内部結合、外部結合など様々な種類があり、詳細は「DML」の章で解説します。
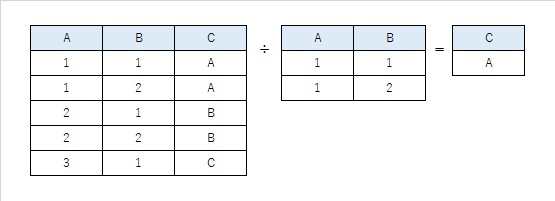
商 (Division)
少し複雑な演算で、あるテーブルの全ての値を持つ行を、別のテーブルから見つけ出す操作です。例えば、「全ての科目を履修した学生」を抽出するような場合に利用します。
集合演算
集合演算は、数学の集合論に基づいた演算で、二つのテーブル(リレーション)を対象とします。和、差、積の演算を行うには、二つのテーブルの列数(次数)が同じで、対応する列のデータ型に互換性がある(和両立である)必要があります。
和 (Union)
二つのテーブルの行をすべて合わせた結果を返します。SQLの`UNION`に相当し、重複する行は取り除かれます。重複を許す場合は`UNION ALL`を使用します。記号は「∪」で表されます。
SELECT * FROM A UNION SELECT * FROM B;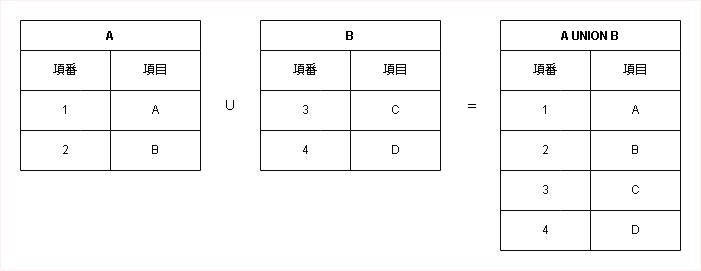
共通 / 積 (Intersect)
二つのテーブルの両方に存在する行のみを返します。SQLの`INTERSECT`に相当します。記号は「∩」で表されます。
SELECT * FROM A INTERSECT SELECT * FROM B;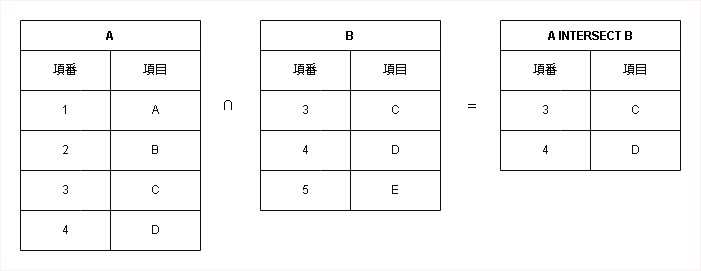
差 (Except)
最初のテーブルに存在し、かつ二番目のテーブルには存在しない行を返します。SQLの`EXCEPT` (または `MINUS`) に相当します。記号は「-」で表されます。
SELECT * FROM A EXCEPT SELECT * FROM B;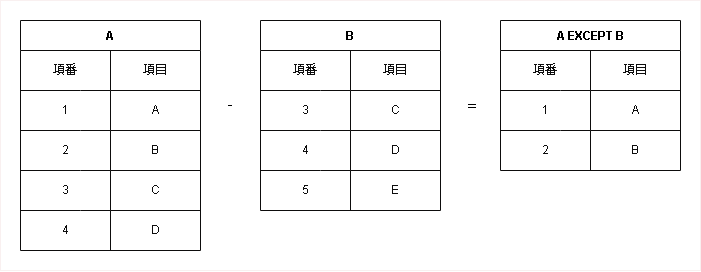
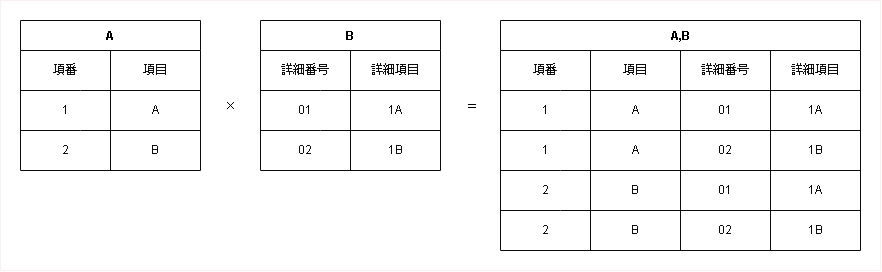
直積 (Cartesian Product)
二つのテーブルの行の、全ての可能な組み合わせを返します。SQLではテーブルをカンマで区切る (`FROM A, B`) ことで実行されますが、結果が膨大になるため意図しない利用には注意が必要です。
SELECT * FROM A, B;