データベース設計
データベースの設計は一般的に要件収集と分析から始まり、物理設計まで実施します。
- (1) 要件収集と分析
- (2) 概念スキーマの設計
- (3) 論理スキーマの設計
- (4) 物理スキーマの設計
本サイトでは要件収集と分析については記載せず、概念スキーマの設計から記載していきます。
データベースの設計は、データベーススペシャリストの午前2の過去問題を作成するための設計になります。
データベース設計の概要として3層スキーマがあります。
3層スキーマとは、データベースの構造を外部スキーマ(ユーザ参照)・概念スキーマ(テーブル設計)・内部スキーマ(保存)として3層に分けたものです。
以下に3層スキーマの詳細を記載します。
[3層スキーマ]
- 外部スキーマ:システム利用者がデータ参照(ビューなど)
- 概念スキーマ:システム対象になるデータそのもの(テーブル)
- 内部スキーマ:概念スキーマの物理データの格納(Indexなど)
外部スキーマはビューの章で説明します。
内部スキーマはデータベース詳細の物理スキーマの設計で説明します。
概念スキーマは次の節から説明します。
スキーマは主にデータベースの設計(スキーマ設計)を指しますが、さまざまな意味で利用されます。
PostgreSQLには構造としてのスキーマがありますが、それはデータベースの配下にあるスキーマです。
PostgreSQLでは、「データベース」 → 「スキーマ」 → 「テーブル」のような構成になり、スキーマを定義しなければ「public」のスキーマが利用されます。
また、スキーマごとにテーブルを作成できるため、データベース内に異なるスキーマであれば同じテーブル名が作成できます。
その他にも後述する関係スキーマなどがあり、会話のニュアンスで何のスキーマについて話しているのかを判断する必要があります。
概念スキーマ
最初に概念スキーマの設計から進めます。
概念スキーマとは、データベースの論理設計で、内部スキーマと外部スキーマの間に位置し、エンティティやデータ項目を設計します。
エンティティは後ほど説明しますが、データの集まりを指します。
アウトプットとして、E-R図やテーブル設計書などがあります。
以下が概念スキーマの流れになります。
[概念スキーマの流れ]
- (1) 概念モデル作成
- (2) 概念モデル検証
- (3) 論理データモデル作成
- (4) 論理データモデル検証
- (5) 物理データベースの設計
概念データモデルの作成
概念データモデルを作成するには、必要なデータを定義し標準化する必要があります。
まず、全体を俯瞰して見れるようにするために概念だけを記載します。
また、概念データモデルでは、DBMS(PostgreSQL、MySQL、MS SQLなど)に依存しない設計が求められます。
データベーススペシャリストの過去問題で概念データモデルを考えた場合は以下のようになります。
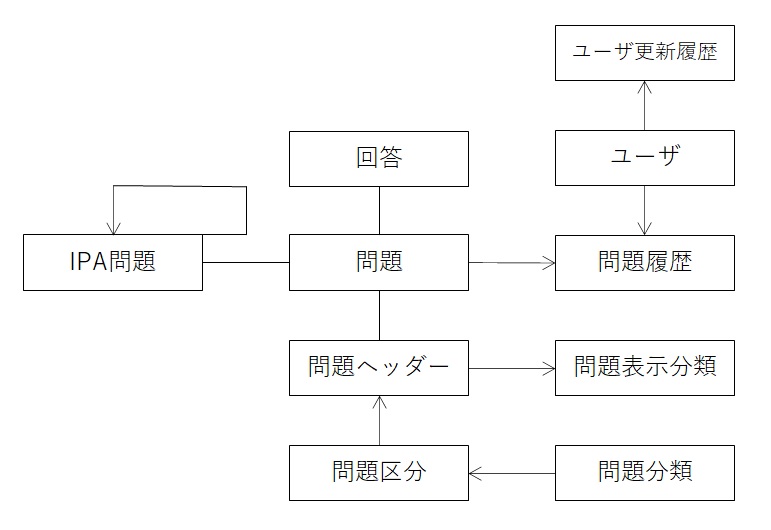
概念データモデルでは、エンティティだけを記載していくイメージです。
例えば、ユーザというエンティティがあったとすれば、その中には名前、性別、年齢、住所などの属性が含まれます。
エンティティ同士をリレーションしていくのが、概念データモデルになります。
概念データモデルを作成するためには、データの定義、標準化、関係、関係代数、関係モデル、E-R図の表記方法、正規化について学ぶ必要があります。
E-R図の表記方法にはいろいろありますが、本サイトでは実際のデータベーススペシャリストの試験に合わせるため、IPA記述(Batchmanに近い記法)の内容で説明していきます。
データの定義
データベースを設計するには、最初にデータを定義する必要があります。
本サイトでは、プロジェクトに記載した「データベーススペシャリストの過去問題」が行えるサイトを開発するためのデータベースを設計していきます。
そのため、データベーススペシャリストの過去問題を行えるようなWebサイトを開発するためには、どのような表示で何の情報が必要になるかを考え、必要なデータを定義していきます。
前述している通り、一つのデータの集まりがエンティティになります。
データ定義は必ずしも同じ内容になるとは限りませんが、以下を考慮して本サイトではエンティティごとに定義しています。
- (1) 実施年度・問題番号・問題内容(テキスト・図)・回答(選択)が必要
- (2) 正解・不正解の判定(答え)とその回答の解説
- (3) 過去の回答結果の履歴表示
- (4) ユーザ定義(ゲスト含む)
<データ定義>
【ユーザ】
- ユーザID
- ニックネーム
- パスワード
- 性別
- 年代
- 作成日
【問題データ】
- 分類:今後IPAに限らず他の分類の試験を実施する
- 区分:他のIPA試験の過去問と分けるため(ネットワークスペシャリストなど)
- 実施年度
- 問題番号
- 問題内容
- 図
- 回答アの内容
- 回答イの内容
- 回答ウの内容
- 回答エの内容
- 回答
- 解説
- 作成日
- 更新日
【問題回答ログ】
- 実施年度
- 問題番号
- 分類
- 実施したユーザID
- 回答内容
- 実施日
本サイトでは、上記の内容で進めていきます。
今回は、データベーススペシャリストの過去問題に基づくアウトプット(問題・答え、レシート・帳票など)から必要なデータを定義していくボトムアップのアプローチを採用しています。
ボトムアップのアプローチとは、問題や回答などアウトプットされている情報から全体を構築するイメージです。
トップダウンからアプローチする方法もあります。
ボトムアップとは反対で全体からデータを定義したり、業務フローからデータを定義していきます。
トップダウンアプローチでは、機能追加やアウトプットがない場合によく利用されます。
どちらのアプローチでもデータ定義は可能ですが、ボトムアップのアプローチで設計したほうがデータ定義時に項目の漏れが少なくてすみますが、既存システムに似通ったシステムになる欠点があります。
標準化
次に、定義したデータ項目の標準化を進めていきます。
標準化とは、エンティティ「ユーザ」のユーザIDは数値で、ニックネームは文字であるなどを定義することです。
扱っているデータがどのような値になるのかを明確にします。
PostgreSQLのドキュメント「PostgreSQL 14.0文書」の「8. データ型」を参照することで、どのようなデータ型が使えるかが分かります。
標準化を行う際の注意点として、どのDBMS(MySQL・MS SQLなど)でも開発が進められるように、文字列の場合はvaryingなどを使用せず、文字・数値などデータベースに依存しない形式を考慮する必要があります。
また、文字・数値・記号など、何でも入れられるような文字列は万能ですが、数値や日付型など、使用するデータに最適なデータ型を選択することが標準化では重要です。
例えば、数値を使用するメリットには、データ量の削減、インデックスが効きやすくなる(パフォーマンス向上)ことや、範囲検索が行える点などがあります。
また、入力間違いを防ぐことでバグの発生を抑え、データの整合性を保つためにも、最適なデータ型を考える必要があります。正しいデータ型の設計を行うことで、プログラムの開発から運用・テストまでの工数を削減できます。
数値を使用する例として、2016年から2019年の問題を抽出したい場合、BETWEENを使用すれば簡単に記載でき、インデックスが設定されていれば抽出も高速です。
・テキストの場合:select * from 問題 where 実施年度 = '2016' or 実施年度 = '2017' or 実施年度 = '2018' or 実施年度 = '2019'
・数値の場合:select * from 問題 where 実施年度 between 2016 and 2019
また、文字として定義した場合、間違えて全角の「2019」と入力すると検索に引っかからなくなりますが、数値で定義していれば全角の「2019」は入力時にエラーになり、気づくことができます。
上記を踏まえて、本サイトでは以下で進めていきます。
【ユーザ】
- ユーザID:数値とします。
- ニックネーム:文字列とします。
- パスワード:暗号化された文字列とします。
- 性別:数値とします。
- 生年月日:日付とします。
- 作成日:日付とします。
【問題データ】
- 分類:IPAなど分かりやすくするため文字列とします。
- 区分:データベーススペシャリストなど分かりやすくするため文字列とします。
- 実施年度:試験用のファイルは 西暦のため、数字とします。
- 問題番号:数値とします。
- 問題内容:文字列とします。
- 図:画像を表示させるために、URLとし文字列とします。
- 回答アの内容:文字列とします。
- 回答イの内容:文字列とします。
- 回答ウの内容:文字列とします。
- 回答エの内容:文字列とします。
- 回答:文字列とします。
- 解説:文字列とします。
- 作成日:日付とします。
- 更新日:日付とします。
【問題回答ログ】
- 実施年度:問題データと合わせて、数字とします。
- 問題番号:数値とします。
- 分類:文字列とします。
- 実施したユーザID:数値とします。
- ニックネーム:文字列とします。
- 回答:文字列とします。
- 実施日:日付とします。
標準化を進める上で、定義したデータにどのようなデータが入るかを可視化することで誤りを防ぐことができます。
問題データをエクセルで作成すると、以下のようになります。このデータがテーブルとなります。
「問題データ」がテーブル名となります。
横に新たな問題データが追加されていくイメージです。
※モバイルファーストで表示できるようにするため、あえて縦書きにしています。
- 分類
- IPA
- 区分
- データベーススペシャリスト
- 実施年度
- 2020
- 問題番号
- 1
- 問題内容
- 図のデータベース1,2は互いのデータの複製をもつ冗長構成である。クライアントからの更新・参照要求を受けたデータベースサーバ(以下、サーバという)は直下のデータベースを更新・参照し、他方のサーバにデータ更新を通知する。通知を受けたサーバは直下のデータベースに更新を反映する。サーバ1,2間のネットワークが分断し、データ更新を通知できなくなったとき、CAP定理で重視する特性(C,A,P)に対するサーバの挙動のうち、適正な組み合わせはどれか。
- 図
- /ipa/db/2020/1.jpg
- 回答ア
- ア
- 回答イ
- イ
- 回答ウ
- ウ
- 回答エ
- エ
- 回答
- イ
- 解説
- サーバが持つ挙動の中で適正なのは、可用性(Availability)と分断耐性(Partition Tolerance)です。整合性(Consistency)はこの状況では確保できないため、両サーバの整合性が損なわれる可能性があります。
- 作成日
- 2021/5/29 16:00
- 更新日
- 2021/5/29 16:00