概念データモデル作成
概念データモデル作成についてするための内容について学びましたので、実際に概念データモデルを作成していきます。
全体を俯瞰して見れるようにするための概念を記載していきます。
また、データベースの設計を行うには完成されるアプリがどのようなものになるかを知っておく必要があります。
(本来はアプリのアウトプットから考えていくことで、項目の漏れが少なくなります。)
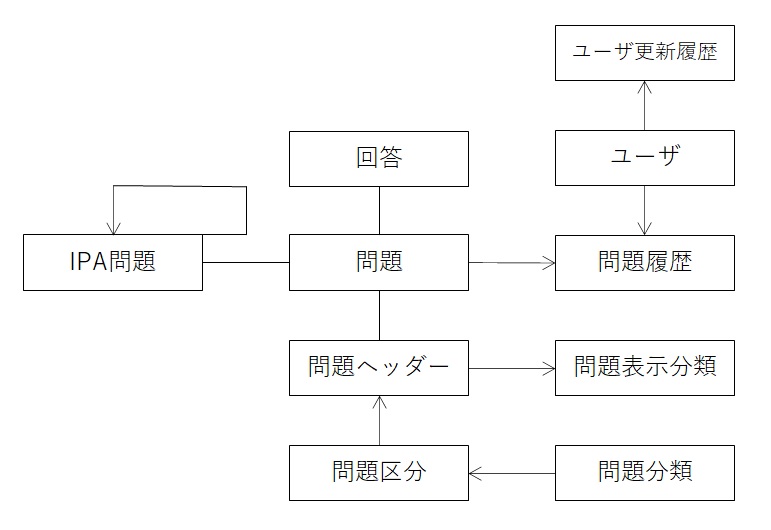
概念を考えたときにユーザ事に回答が必要ですので、ユーザ・問題・回答は最低限必要になります。
データ容量は極力減らす必要がでてきますので、IPAは別に用意いたします。
ユーザの更新履歴や、問題の履歴が必要です。
問題の分類・区分も必要になります。
また、IPAの問題を参照していただくと分かるのですが、文字だけでは表示できず図を表示するパターンもあります。
そのため、表示タイプがアプリ側には必要になり、そのタイプに応じて画像を出したりする必要があります。
※上記の考えは、主観であり必ず正しいわけではありません。
上記から考えたのが、以下のようなイメージになります。
概念データモデル検証
前章で作成した概念データモデルを検証していきます。
ユーザと問題が多対多で結びつけるような記載をされる場合もありますが、その場合は極力中間のものを作成するようにします。
多対多の場合、論理データモデルに変換する場合に非正規形になりますので中間のものを作成してその中間のものがリレーションしているエンティティを外部キーとして1対多にする必要があります。
この中間エンティティを連関エンティティといいます。
前章の概念データモデルのユーザ↔問題ではなく、問題→問題履歴←ユーザになっているイメージです。
ユーザ更新履歴は、1人のユーザに対して複数ありますので1対多表記です。
問題-回答は問題1つにつき回答は一つですので、1対1です。
問題-IPA問題も問題1つにつきIPAの年や問題番号は1つですので1対1です。
IPA問題には過去に同じ問題がありますので、自己参照があり自身に1対多としています。
問題分類(IPAなど)に対して問題区分(データベーススペシャリスト・ネットワークスペシャリストなど)は複数あり、それにリレーションしている問題ヘッダーも複数ありますので、問題ヘッダー←問題区分←問題分類としています。
問題ヘッダは1つ問題に一つですので、問題-問題ヘッダとして1対1です。
問題にはテキストのみ、画像付きなどの問題表示分類がありますので、1対多としています。
論理データモデルの作成
前章で作成した概念データモデルから論理データモデルへの変換をしていきます。
論理データモデルは、特定のデータベース管理システム(DBMS)に依存しないで、実装できるレベルにしたものです。
特定のデータベース管理システム(DBMS)に依存しないというのは、主キーや外部キーなどは一般的に使用可能ですがデータ定義はデータベース管理システム(DBMS)によって異なる場合がありますのでそこまでは記載しません。
前章で学習したE-R図の記載方法です。
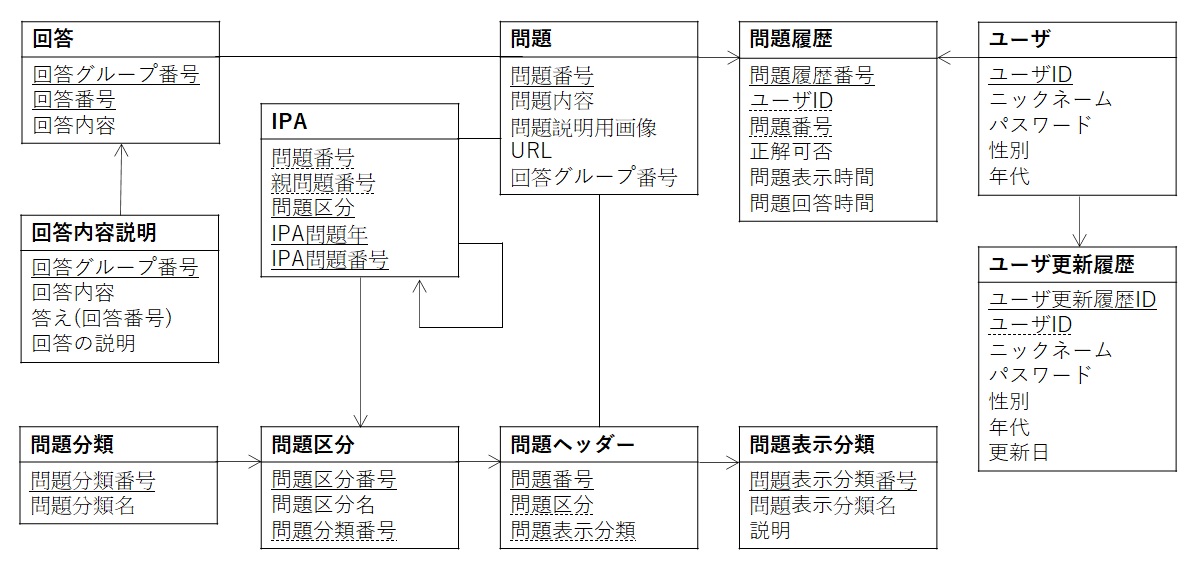
概念データモデルにどのようなカラムがあり、そのカラムがどのようにリレーションしているのかを記載したイメージです。
以下のようなイメージになります。
論理データモデルの検証
概念データモデルを論理データモデルに変更しても、概念データモデルの設計に問題ないか検証していきます。
前章で学習した正規化についても考えてみます。
ユーザ:個人情報にならない程度の情報に留めておきます。主キーはユーザIDです。候補キーもそれだけですので、推移的関数従属もしていません。
ユーザ変更履歴:ユーザ変更履歴IDが主キーです。外部キーとしてユーザIDがあります。こちらも推移的関数従属はしていないです。
問題:問題番号が主キーです。回答グループ番号を外部キーにしていないのは回答を登録する前に問題を登録する可能性があるためです。
問題ヘッダー:問題区分と問題表示分類を組み込めば不要になりますが、IPAで過去問がある場合は、問題ヘッダーのみがあれば事足りると判断しましたので敢えて分割しています。分割する必要はないです。
問題履歴:問題履歴番号が主キーになり、ユーザIDと問題番号を主キーにしています。
回答:回答グループ番号と回答番号で複合キーとしています。
回答内容説明:正規化したのは、回答に含めてしまうと全レコード修正しないといけず、修正間違いがあれば矛盾が生じます。
IPA:問題番号をキーとして、IPA問題のみのオプションデータとします。
問題区分:主キーは問題区分番号として、問題分類番号を外部キーとします。
問題分類:主キーは問題分類番号とします。
問題表示分類:主キーは問題表示分類番号とします。
おさらいになりますが、着目することを以下に記載いたします。 (1) 冗長性を排除して1事実1箇所になっていること (2) 情報無損失分解になっていること(結合すれば元に戻せること)
物理データベースの設計
物理データベースの設計を行うには、運用・保守を含めた要件をきちんと整理する必要があります。
※実業務では、1台のサーバにインストールしてそのまま利用すればいいわけではありません。
- (1) テーブル設計
- (2) データ容量の計算(何年利用するのか。)
- (3) 性能要件
- (4) バックアップ要件
- (5) 障害発生時の対応
- (6) セキュリティ
- (7) 運用分析