物理データベースの設計
物理データベースの設計を行うには、運用・保守を含めた要件をきちんと整理する必要があります。
物理設計は運用に関わる内容になり、ハードウェア(H/W)やソフトウェア(S/W)の構成を最初に検討する必要があります。
近年では、クラウドファーストになってきており、Paas(Platform as a Service)を利用することでサーバにインストールすることやバックアップをクラウド業者が自動で行うケースも増えております。
クラウドなので、データが消えないなどは言い切れませんので、運用などの検討は必要です。
データベースで必要になる物理設計を次に記載します。
- 設計
- 性能要件
- バックアップ要件
- 障害発生時の対応
- セキュリティ
- 運用分析
設計
設計では、論理データモデルで設計されたエンティティやリレーションを物理テーブルに変換します。
具体的には、各テーブルのカラム、データ型、参照制約(主キー、一意キー、外部キーなど)を定義します。
ビューで表示を制限したり、トリガーを利用してテーブル行の変化があった場合に別のレコードの値を変更したりする設計も考慮します。
参照制約
参照制約とは、テーブル同士の関係性を保ち、データの整合性を保証するために設けられる制約です。
特定の列または列の組み合わせが、他のテーブルの列と対応していることを保証し、誤ったデータが保存されるのを防ぎます。
参照制約の動作は、以下になります。
-
CASCADE
親テーブルの行が更新または削除されたとき、それに依存する子テーブルの行も自動的に更新または削除されます。
-
SET NULL
親テーブルの行が削除または更新された場合、子テーブルの外部キー列にNULLが設定されます。外部キー列はNULLを許可する必要があります。
-
SET DEFAULT
親テーブルの行が削除または更新された場合、子テーブルの外部キー列にデフォルト値が設定されます。
-
NO ACTION
親テーブルの主キーに対する更新や削除を行っても、子テーブルの外部キーには影響を与えません。
レコードを更新または削除する際に、そのレコードに関連する外部キーを持つ子テーブルが存在する場合、エラーが発生します。 -
RESTRICT
子テーブルに依存するデータがある場合、親テーブルの主キーを更新または削除することができません。
レコードを更新または削除する際に、そのレコードに関連する外部キーを持つ子テーブルが存在する場合、エラーが発生します。
制約検査のタイミングは以下になります。
-
即時検査(Immediate)
SQLの実行終了時に、その時点で影響を受けたすべての行に対して制約が検査されます。
-
遅延検査(Deferred)
トランザクションが完了する(コミットされる)タイミングで、すべてのSQLの結果に対して制約が検査されます。
トリガー
トリガーとは、テーブルに対して挿入、更新、削除といった変更操作が行われた際に、自動的に定義された処理を実行する機能です。
変更の前に処理を実行するのが「BEFOREトリガー」、変更の後に処理を実行するのが「AFTERトリガー」といいます。
AFTERトリガーは、他のAFTERトリガーに連鎖して処理を実行することも可能です。
また、変更前の行と変更後の行にそれぞれ相関名を指定することで、古い値と新しい値を参照できます。
性能要件
データベースの性能は、サーバのハードウェア(CPU、メモリ、ディスクの速度)やDBMS、そしてデータベースの設計・実装に依存します。
データベースの実装では、クエリ実行計画の解析やチューニングを行い、性能の最適化を図ります。
プロジェクトによっては、スループット(処理能力)が要件として求められることがあります。
スループットとは、例えば「数秒以内にどれだけの処理を行えるか」や「同時にアクセスできる最大数が〇〇件まで対応可能である」といった性能指標のことです。
データベースの性能見積
データベースの性能を見積もる際は、サーバーのハードウェアの性能を確認する必要があります。
ハードウェアには以下の3つの要素があります。
-
CPU速度
データベースのレコードを処理する時間
-
ディスク速度
ディスクからレコードを読み書きする時間(I/O)
-
バッファ速度
メモリ上にキャッシュされたレコードを読み書きする時間(I/O)
データベースの処理速度は、基本的に「CPUの速度 + バッファ処理の速度」で計算できます。
ただし、ディスクアクセスが必要な場合は「ディスクの速度」も加算する必要があります。
バッファヒット率は、データがメモリ上のバッファから取得できる割合を示します。
例えば、バッファヒット率が90%なら、レコードの90%はメモリから取得され、残りの10%はディスクから読み込む必要があります。
次に、具体的な例として、IPAの計算方法に基づき、10GBのテーブルデータ[2000ページ分)を処理する時間を求めます。
<前提条件>
- CPU速度:10ページ秒
- ディスク速度:100Mバイト/秒
- バッファ速度:1000Mバイト/秒
- バッファヒット率:60%
-
CPU時間
2000ページ ÷ 10ページ/秒 = 200秒
-
ディスク処理時間
10GB(10000MB) × (1 - バッファヒット率0.6) ÷ 100MB/秒 = 40秒
-
バッファ処理時間
10GB(10000MB) × バッファヒット率0.6 ÷ 1000MB/秒 = 6秒
最後に、これらを合計して、CPU時間 + ディスク処理時間 + バッファ処理時間 = 246秒となります。
このハードウェアの性能で、10GBのテーブルデータ(2000ページ分)を処理するのに掛かる合計時間は246秒です。
これまではハードウェアに関する説明のみでしたが、実際にはデータベースのパフォーマンスを向上させるためにはチューニングを行って読み込むページ数を削減します。
その一つの方法が「インデックス(INDEX)」の利用です。
インデックスを使うと、テーブル内のデータに索引(インデックス)をつけて効率的に検索できます。
インデックスがない場合、テーブル全体を最初のページから順に読み込む「シーケンシャルスキャン」が行われます。
これは、例えばテーブルデータが2000ページある場合、最大で2000ページ全てを探索する必要があるということです。
一方、インデックスを使用した「インデックススキャン」では、条件に合う行を絞り込んでから検索を行うため、探索するページ数が大幅に減少します。
例えば、特定の会員Aを探す場合、テーブルスキャンでは2000ページ全てを探索する可能性がありますが、インデックススキャンなら1ページで済むこともあります。
また、テーブルを結合している場合、それぞれの結合されたテーブルごとにデータを探索する必要があります。
特に、外側のテーブル(外部テーブル)の結果ごとに、対応するデータを探す処理が行われます。
結合演算を使用する場合、結合元のテーブルと結合先のテーブル、それぞれで探索する時間を計算する必要があります。
データの格納方法
前述している通り、PostgreSQLでは1つのテーブルに1つのファイルが作成されます。
その後に、容量が増加してファイルの制限に達すると別のファイルを作成していきます。
容量が増加していき、全てのファイルを参照して中のデータを走査するのはとても非効率です。
ある条件においてファイルを分けることにより、条件で分けたファイルのみ参照することをパーティショニングといいます。
パーティショニングには以下があります。
- ハッシュ
→レコードの特定のデータ項目の値を引数としてハッシュ値としてキーを作成し、そのキーで分割
- レンジ
→日付の範囲(2009年)などで分割
- リスト
→任意の値でグループ化して分割
多版型同時実行制御(MVCC)
複数のユーザから同時に接続がきた場合に一貫性を保ちつつ並行処理を可用性を向上させます。 同時実行される二つのトランザクションのうち、先発のトランザクションがデータを更新し、コミットする前に後発のトランザクションが同じデータを参照すると、更新前の値を返します。
楽観的な手法があり、データに対してのロックは行わずに、更新対象のデータが他のトランザクションと競合がなかったことを確認してからコミットします。
Base特性
Base(Basically Available Soft State Eventual Consistand)特性とは、多数の人が使用できるようにするため複数で負荷分散などを行い可用性を重視し、応答は通信・サーバ障害などで一貫性が保てない場合もありますが復旧後に最終的に一貫性がある状態になるような特性です
HA クラスタリング
クラスタリングとは、複数台のサーバで本番系と待機系に分けて本番系がダウンした場合に待機系が本番系に切り替わり、ダウンタイムを少なくして可用性を高めます。 1箇所に集約して管理する集中型と複数の拠点に設置してデータを同期しながら管理する分散型があります。
集中型のことをシェアードエブリシングといい、分散型をシェアードナッシングといいます。
- シェアードエブリリング
→アクティブ―アクティブ構成によって負荷分散を行うことによって、サーバリソースの有効活用が可能になり、さらにデータが共有されているので、1台のサーバの障害発生時でも処理を継続できます。
- シェアードナッシング
→データを複数の磁気ディスクに分割配置し、さらにサーバと磁気ディスクが1対1に対応しているので、複数サーバを用いた並行処理が可能
分散型は集中型に比べて以下メリットとデメリットがあります。
-
[メリット]
- ・読み取りだけであれば、別々のデータベースが応答可能なため負荷分散・アクセス向上
- ・東京A店データベース、北海道B店データベースなどとしたときに北海道B店で問題が発生しても東京A店は継続可能
- ・ディスクがクラッシュしたなどでデータが参照できなくても別のデータベースで保持
-
[デメリット]
- ・コスト増加
- ・書込遅延(2相コミット:データ書込時に各データベースに書き込めるかの確認が必要で書込み可能ならコミットするができない場合はロールバック)
- ・管理の複雑化(各データベースの障害発生・各データベースへの接続失敗などの処理)
また、分散型ではコストが増加して複雑になり、透過性(位置・移動・分割・重複・障害)も意識する必要があります。
分散型でいう透過性は、分散型データベースが複数のサーバになりその接続先、データ保存・重複格納・分割格納、障害発生を意識することなく利用者が利用できることです。
[分散型] 結合として次があります。
・入れ子ループ法:データを1行ずつ送信して、受信側で1行ずつ順次結合処理を実施
・セミジョイン法:結合する列だけを送信して受信側で結合処理を実施
・ハッシュセミジョイン法:結合する列をハッシュ値で送信して受信側で結合処理を実施
・マージジョイン法:結合するテーブルをソートして送信して受信側で結合処理を実施
また、分散型の定理としてCAP定理があります。
これは、Consistency(一貫性)・Availability(可用性)・Partition-tolerance(分断耐性)の略でその3つのうち、2つまでしか特性を満たせれません。
特性としてはBase(Basically Available Soft State Eventual Consistand)があります。
多数の人が使用できるようにするため複数で負荷分散などを行い可用性を重視し、応答は通信・サーバ障害などで一貫性が保てない場合もありますが復旧後に最終的に一貫性がある状態になるような特性です。
分散型でのトランザクションには1相コミットと2相コミットがあります。
2相ロック方式の場合、トランザクションは必要なすべてのロックを獲得してからロックを解除します。
分散データベースでは、①「コミット確認」→②「トランザクション処理」→③「コミット」の流れになります。
クラスタリングは以下の手順で切り替わりが発生します。
- 本番系サーバと待機系サーバが接続しているスイッチに対して,待機系サーバから,接続しているネットワークが正常かどうかを確認
- 待機系サーバは,本番系サーバのディスクハートビートのログ(書込みログ)をチェックし,ネットワークに負荷が掛かってハートビート信号が届かなかったかを確認
- 待機系サーバは,本番系サーバの論理ドライブの専有権を奪い,ロック
- 本番系サーバは,OSに対してシャットダウン要求を発行し,自ら強制シャットダウン
ディスク冗長化
データベースを複数用意して性能を向上していますが、ディスクを冗長化することで性能を向上させる方法もあります。
その1つがRAIDです。 RAIDはアクセス向上と冗長化が望めます。
RAIDには、ハードウェアRAIDとソフトウェアRAIDがあり種類も以下のようにあります。
RAID0:ストライピングでデータを複数のディスクに分割して記憶します。アクセス向上しますがどれか一つでもディスクが故障するとデータが参照できなくなります。
RAID1:ミラーリングです。データを複数のディスクに同じように記憶します。アクセスは向上しませんが、冗長化します。
RAID10:RAID1とRAID0を組み合わせたもので、アクセス向上と冗長化の両方が行えます。。
RAID5:3台1以上のディスクが必要で、複数のディスクにデータを分割して記憶して1つのディスクにパリティを記載します。1台のディスクが故障しても残りのデータとパリティから計算してデータを参照できるようにします。アクセス向上と冗長化の両方が行えます。
RAID6:4台1以上のディスクが必要で、複数のディスクにデータを分割して記憶して2つのディスクにパリティを記載します。アクセス向上と冗長化の両方が行えます。
一般的に+がつくとホットスペアのことで予備ディスクで、故障したときに自動で切り替わります。
また、パーティション分割して一つの大きなテーブルを複数に分割して保存することで検索を高速化することもできます。
バックアップ
バックアップは、主に機器の障害や誤操作によるデータ損失に備えて、データをリカバリ(回復)できるように実施します。
PostgreSQLでは、バックアップ用のコマンド(pg_dumpやpg_basebackupなど)や、リストア用のコマンド(restoreなど)を使用します。
以前は、磁気ディスクやDAT(テープドライブ)に保管するのが一般的でしたが、現在ではクラウドサービスを利用するのが主流になっています。
バックアップには、フルバックアップ、増分バックアップ、差分バックアップ、レプリケーション、Point-in-Time Recovery(特定時点復元)などの方法があります。
データベース全体やテーブル単位でバックアップを行うことも可能です。
バックアップには、オンラインとオフラインの方法があります。
オンラインバックアップでは、ネットワーク越しにデータベースサーバに接続してバックアップを行います。
オフラインバックアップは、サーバ内(ローカル)でバックアップを実行します。
フルバックアップ
全てのデータベースをバックアップします。
PostgreSQLでは、DBクラスタ全体をバックアップします。
別のサーバで稼働させる場合、設定ファイルなどを変更しているならそのファイルの移動も必要です。
データベースサーバが停止できるなら、DBクラスタ全体のディレクトリをzipなどで圧縮して移動することもできます。
フルバックアップのメリットは、リストア時に1つのファイルだけですみません。
デメリットは、ファイルのサイズが大きくなりますので、バックアップの時間が掛かります。
増分バックアップ
フルバックアップまたは前回の増分バックアップから変更があった内容だけをバックアップします。
PostgreSQLでは、17から対応しています。
増分バックアップの回数分リストアが必要になります。
「フルバックアップ」 → 「増分バックアップ1回目」 → 「増分バックアップ2回目」 → 「増分バックアップ3回目」と増分バックアップが3回発生した場合、「フルバックアップのリストア」 → 「増分バックアップ1回目のリストア」 → 「増分バックアップ2回目のリストア」 → 「増分バックアップ3回目のリストア」とバックアップの順と同じようにリストを実施します。
増分バックアップのメリットは、レコードの追加が多い場合はバックアップ容量を削減することができます。
デメリットは、レコードの変更が多い場合は不要なデータが発生してしまいます。
差分バックアップ
フルバックアップから変更があった内容をバックアップします。
PostgreSQLでは、差分バックアップはありません。
フルバックアップからの差分を毎回バックアップします。
フルバックアップと差分バックアップの2つを利用してバックアップとリストアをします。
差分バックアップのメリットは、レコードの変更が多い場合でも最新の情報しか持ちませんので不要な変更情報を保持しません。
複製
バックアップではありませんが、複製はミラーリングやレプリケーションともいい、サーバをN台用意してデータベースをN台で同期します。
同じデータベースが2つ用意されますので、1台のサーバが故障してももう1台で稼働できます。
そのため、災害復旧(DR)、高可用性、負荷分散、負荷分散(読み込みを分散する。)できます。
デメリットとして、ネットワークの通信遅延などにより最新の情報になるまで若干時間が掛かったり、複雑な設定や運用コストが高くなります。
Point-in-Time Recovery
Point-in-Time Recoveryは、トランザクションログのバックアップを利用して、特定の時点までの状態にデータベースを復元します。
誤った入力をしてしまった場合など、その直前まで戻すことが可能です。
PostgreSQLでは、WALを利用して実施します。
(5) 障害発生時の対応
1台のサーバでデータが復旧できないような障害が発生した場合は、バックアップデータからリストアを実施します。
ストリーミングレプリケーションなどで冗長化している場合であれば、別のデータベースが入っているサーバをマスターにして各クライアントの向き先を変更するかマスターの設定維持させるかで復旧させます。
また、記憶媒体を冗長化してRAIDを構成にすることで、1台の記憶媒体で障害が発生しても停止せずに記憶媒体を交換することで復旧させることも可能です。
(6) セキュリティ
データベースの脅威として考えられるのは、不正アクセス、データ盗聴が主に考えられます。
まず不正アクセス・データ盗聴に関しては、接続方法の設定で改善できます。
「pg_hba.conf」で設定することが可能で、初期設定ではローカルからの接続のみが可能になっています。
これであれば、OSにログインできない限りはアクセスできませんが、環境によってはネットワーク経由でのアクセスが必要になったりします。
その場合、ROLEにアクセス可能なデータベースなどを適正設定し、接続タイプを「hostssl」の設定をすることで、セキュアな接続になりデータ盗聴の対策にもなります。
SSL証明書なども確認できます。
以下が、「pg_hba.conf」の中身で最初(Local、host)が接続タイプになります。
次(postgres,all)がデータベースで次(user,all)がユーザになります。
その次(空白、127.0.0.1)がアクセス可能なIPアドレスで、最後が認証方式(trustは許可)です。
(7) 運用分析
データベースの運用分析は、データベースが安定して動作するように日々の運用状況を監視して、改善点を特定するために実施します。
前述している性能要件、バックアップ要件、セキュリティなどを考慮します。
具体的には、次の運用状況を確認します。
- 遅いクエリ(スロークエリ)が発生していないかを確認する。
- リソースの使用状況(CPU、メモリ、ディスクI/O)が安定しるか確認する。
- ストレージが枯渇していない、データ容量が過度に増加していないか確認する。
- バックアップやリストアがステージングなどの環境で正常に動作しているまたは時間を計測する。
- ログに不正なアクセスや障害が発生していないか確認する。
- データベースやOSなどのバージョンを確認する。
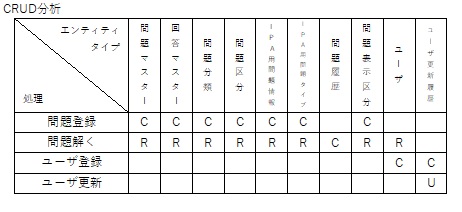
運用分析には、統計情報・CRUD分析を利用します。
CRUD分析は、Create(追加)・Read(参照)・Update(更新)・Delete(削除)の頭文字を合わせたものでCRUD図を作成して各処理が正しいかを分析するものです。
以下のような図になります。