テーブルの物理設計と容量見積もり
1. テーブルの物理設計とは
データベース設計は、概念設計、論理設計、物理設計の3段階に分かれます。物理設計は、論理設計(E-R図など)で定義したデータモデルを、実際にデータベースシステム上に実装するための最終段階です。
この段階では、パフォーマンス、格納効率、保守性を考慮しながら、以下の要素を具体的に決定します。
- テーブル名・列(カラム)名: 論理設計の日本語名から、半角英数字の物理名に変換します。単語間はアンダースコアで繋ぐ「スネークケース」(例: `quiz_type`)が一般的です。
- データ型: 各列に格納するデータに最適なデータ型(`INTEGER`, `VARCHAR`, `TIMESTAMP`など)をDBMSの仕様に合わせて選択します。
- 制約: データの一貫性を保つための制約(主キー制約、NOT NULL制約、一意制約など)を定義します。
- インデックス: 検索パフォーマンスを向上させるために、どの列にインデックスを作成するかを決定します。
標準化(データ型の決定)
データを定義したら定義したデータをどのような形式(データ型)で保存していくかのルールを決めることを「標準化」といいます。
標準化では、適切なデータ型を選ぶことが必要です。定義したデータの整合性を保ちながらパフォーマンスを向上させる設計が非常に重要です。
例えば、問題データの実施年度を「文字列」ではなく「数値」で保存するメリットは以下の通りです。
- データ容量の削減。
- パフォーマンスの向上(インデックスが効きやすい)。
- 範囲検索(例: 2016年〜2019年)が容易になる。
- 「2019」のような全角文字の間違った入力を防ぎ、データの整合性を保てる。
-- テキスト型の場合、複数条件が必要
SELECT * FROM 問題 WHERE 実施年度 IN ('2016', '2017', '2018', '2019');
-- 数値型の場合、範囲指定でシンプルに記述できる
SELECT * FROM 問題 WHERE 実施年度 BETWEEN 2016 AND 2019;
「問題データ」のレコード例
- 分類
- IPA
- 区分
- データベーススペシャリスト
- 実施年度
- 2020
- 問題番号
- 1
- 問題内容
- 図のデータベース1,2は互いのデータの複製をもつ冗長構成である...(中略)
- 回答
- イ
2. データベースの物理的な格納構造
データがディスク上でどのように管理されるかを理解することは、物理設計において重要です。
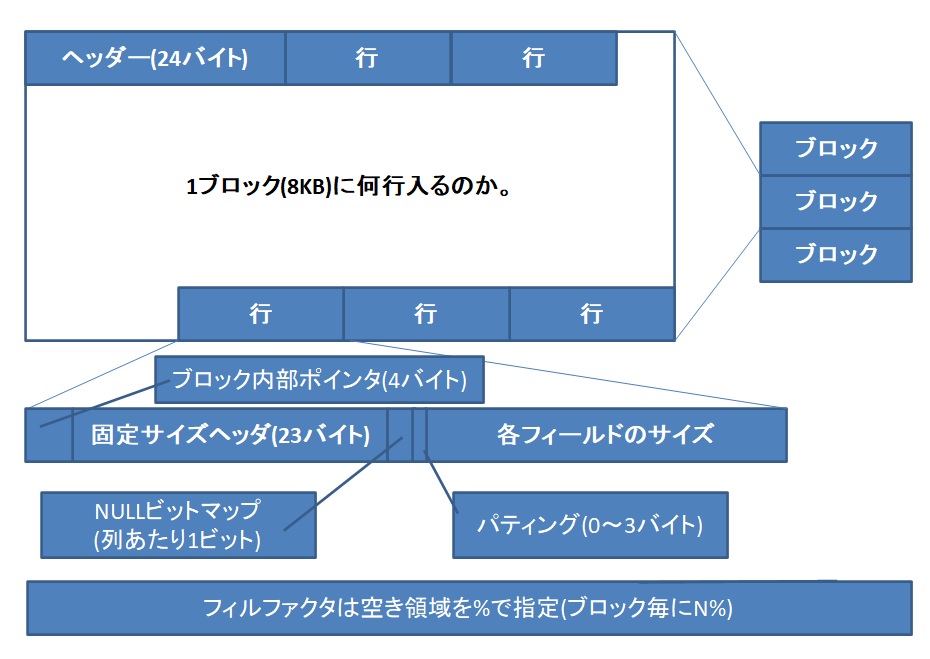
ページ(ブロック)
データベースは、データを「ページ」または「ブロック」と呼ばれる固定長の単位で管理します(PostgreSQLでは通常8KB)。1つのレコードが複数のページにまたがることはありません。
FILLFACTOR(フィルファクター)
データをページに書き込む際、意図的に空き領域を残す割合を設定できます。これが`FILLFACTOR`です。
- なぜ必要か?: `UPDATE`処理でレコードのサイズが大きくなった場合、ページ内に空き領域があれば、データを同じページ内に収めることができます。空きがないと、データを別のページに移動させる必要が生じ、パフォーマンスが低下します。
- メリット: 更新パフォーマンスが向上します。
- デメリット: 空き領域を確保する分、全体のディスク使用量が増加します。
そのため、`UPDATE`が頻繁に発生するテーブルでは`FILLFACTOR`を低め(例: 70%)に設定し、参照が中心のテーブルでは高め(デフォルトの100%)に設定するなど、用途に応じた調整が重要です。
3. データ容量の見積もり
物理設計の重要な作業の一つが、将来のデータ増加を予測し、必要なディスク容量を見積もることです。これにより、適切なハードウェア選定やコスト管理が可能になります。
見積もるべき主な対象は以下の通りです。
- テーブル本体のデータ: レコード数と1レコードあたりのサイズから計算。
- インデックス: 高速な検索のために不可欠ですが、データとは別に容量を消費します。
- ログファイル: トランザクションログ(WAL)や各種ログもディスク容量を消費します。
PostgreSQLの主要なデータ型とサイズ
1レコードのサイズを計算するには、各列のデータ型のサイズを知る必要があります。以下は主要なデータ型とその格納サイズです。
| カテゴリ | 型名 | 格納サイズ | 説明 |
|---|---|---|---|
| 数値データ型 | |||
| 整数 | smallint |
2バイト | 狭範囲の整数 |
integer |
4バイト | 一般的な整数 | |
bigint |
8バイト | 広範囲の整数 | |
serial |
4バイト | 自動増分する整数(主キーで多用) | |
| 文字型 | |||
| 文字列 | varchar(n) |
4バイト + 文字列長 | 上限付き可変長文字列 |
text |
4バイト + 文字列長 | 上限なし可変長文字列 | |
| 日付/時刻データ型 | |||
| 日時 | date |
4バイト | 日付(時刻なし) |
timestamp |
8バイト | 日付と時刻 | |
timestamptz |
8バイト | 日付と時刻(タイムゾーン付き) | |
4. 具体的な容量計算の例
ここでは、簡単なテーブルを例に、実際のデータ容量とインデックス容量を計算してみましょう。
前提条件
- テーブル定義:
- 問題番号: `integer` (主キーインデックスあり)
- 問題区分: `integer`
- 問題表示分類: `integer`
- 見積もり行数: 10,000行
- テーブルFILLFACTOR: 100% (空き領域なし)
- インデックスFILLFACTOR: 70% (30%の空き領域)
- その他: 全列NULLなし、テーブルにOIDは含まない
Step 1: テーブル容量の計算
1行あたりのサイズの計算
24バイト (行ヘッダ) + 4バイト (問題番号) + 4バイト (問題区分) + 4バイト (問題表示分類) = 36バイト1ページに格納できる行数の計算
(8192 (ページサイズ) - 24 (ページヘッダ)) * (100 / 100 (FILLFACTOR)) / 36 (1行のサイズ)
= 8168 / 36 = 226.8... → 226行 (小数点以下切り捨て)必要なページ数の計算
10000 (総行数) / 226 (1ページの行数) = 44.2... → 45ページ (小数点以下切り上げ)テーブルの合計容量
45 (ページ数) * 8192 (ページサイズ) = 368,640 バイト
368,640 / 1024 = 360 KBStep 2: インデックス容量の計算
1エントリあたりのサイズの計算
8バイト (インデックスヘッダ) + 4バイト (問題番号) + 4バイト (タプルポインタ) = 16バイト1ページに格納できるエントリ数の計算
(8192 (ページサイズ) - 24 (ページヘッダ)) * (70 / 100 (FILLFACTOR)) / 16 (1エントリのサイズ)
= 5717.6 / 16 = 357.3... → 357エントリ (小数点以下切り捨て)必要なページ数の計算
10000 (総行数) / 357 (1ページのエントリ数) = 28.0... → 29ページ (小数点以下切り上げ)インデックスの合計容量
29 (ページ数) * 8192 (ページサイズ) = 237,568 バイト
237,568 / 1024 = 232 KBStep 3: 合計容量の見積もり
360 KB (テーブル) + 232 KB (インデックス) = 592 KB
このテーブルとインデックスに必要なディスク容量は、約 592 KB と見積もることができます。